Disclaimer: I recently attended Storage Field Day 19. My flights, accommodation and other expenses were paid for by Tech Field Day. There is no requirement for me to blog about any of the content presented and I am not compensated in any way for my time at the event. Some materials presented were discussed under NDA and don’t form part of my blog posts, but could influence future discussions.
Yesterday, Dell EMC’s Project Nautilus emerged as Dell EMC’s Streaming Data Platform. I wrote this post based on the presentation we were given at #SFD19, and decided to keep the Project Nautilus name throughout my report.
I love it when presenters tell us what world they are coming from, and tie our shared past to new products. Ted Schachter started his career at Tandem doing real-time processing with ATM machines. But as he pointed out, these days there is the capacity to store much more info than he had to work with back in his Tandem days. I loved how he drew a line from past to the present. We really need more of that legacy, generational information shared in our presentations to help us ground new technologies as they emerge.

Data Structures are Evolving
Developers are using the same data structures they’ve used for decades. There is an emerging data type called a stream. Log files, sensor data, and image data are elements you will find in a stream. Traditional storage people think in batches, but the goal with streams is to move to transacting and interacting with all available data in real time, along a single path. By combining them all these data types into a stream you can start to observe trends and do things like the ones shown on the slide above.
Since the concept of streams is pretty new, the implementations you’ll see now are DIY. There are “accidental architectures” based on kafka. Kafka is an open source Apache platform for building real-time data pipelines and streaming apps.
Project Nautilus Emerged to Work with Streams
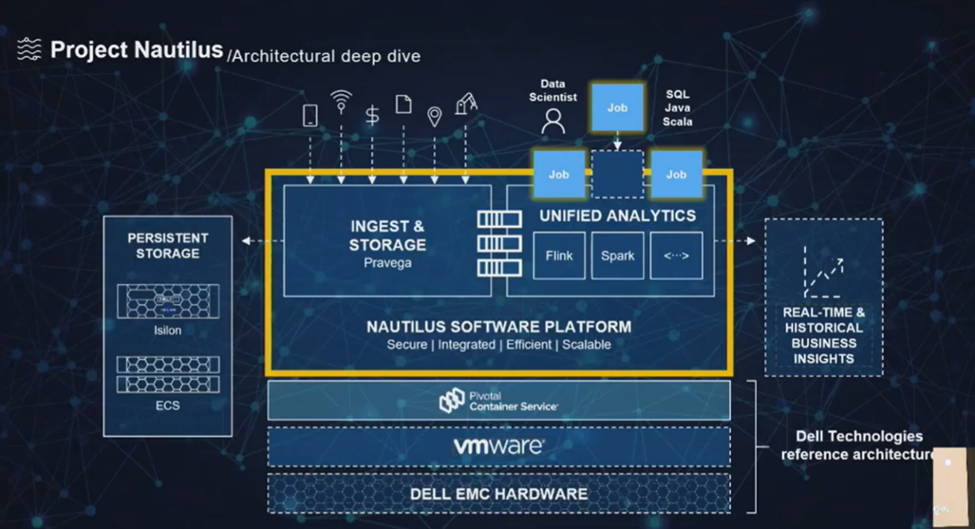
Project Nautilus from Dell EMC Storage is a platform that uses open source tools. They want to build on tools like Spark and Kafka) to do real time and historical analytics and storage. Ingest and storage is via Pravega. Streams come in, they are automatically tiered to long-time storage. Then it is connected to analytic tools like Spark and Flink (which was written specifically for streams). Finally, everything is glued together with Nautilus software to achieve scale (this is coming from Dell EMC Storage after all), and is built on VMware and PKS. More details were to be announced at MWC, so hopefully we’ll have some new info soon.
Real Talk
Product Nautilus emerged as a streaming data platform. This is another example of Dell EMC Storage trying to help their customers tame unstructured data. In this case, they are tying older technology that customers already use to newer technology – data streams. They see so much value in the new technology that they created a way for customers to get out of DIY mode, while at the same time taking advantage of existing technical debt.
This is also a reminder that we’re moving away from the era of 3-tier architecture. There have been hardware innovations, that has led to software innovations. We are going to see more and more architectural innovations. Those who open to learning how tech is evolving will be best positioned apply the lessons learned of the past couple of decades.
How are you learning about the new innovations?


One thought on “Project Nautilus emerged as Dell’s Streaming Data Platform”