AI is a big topic of conversation these days. Some people think the new advances will change human routines and lives. Others think that we should be afraid of these technologies. But to take an informed position, maybe the first thing we should is ask: is it possible to teach machines to be intelligent?
What is AI?
AI, or Artificial intelligence, is the simulation of human intelligence processes by machines. But sometimes applications and services that are marketed as AI are not AI. I really like TechTarget’s definition explanation of the difference between AI, machine learning, and deep learning:
“The term AI, coined in the 1950s … covers an ever-changing set of capabilities as new technologies are developed. Technologies that come under the umbrella of AI include machine learning and deep learning.
Machine learning enables software applications to become more accurate at predicting outcomes without being explicitly programmed to do so. … Deep learning, a subset of machine learning, … use[s] an artificial neural networks structure [as] the underpinning of recent advances in AI, including self-driving cars and ChatGPT.”
After 120 words the term AI still feels pretty fuzzy, doesn’t it? The idea that the term AI has a clear meaning is one of the myths discussed on the AI Myths website. After 65 years we still don’t know the words to describe AI and its underlying technologies.
Let’s use Stanford Professor John McCarthy’s definition, since he was the one that coined it:
The science and engineering of making intelligent machines.
Stanford Professor John McCarthy
How do you teach a machine to be intelligent?
Do machines “learn” how to do things, that people do? Machines don’t really “learn”, instead data scientists train them.
I gave a presentation on this topic at VMworld in 2018 with Tony Foster (aka wondernerd). The presentation was for data center operations folks (virtualization gurus). We talked about how to virtualize the architectures required by machine and deep learning.
We emphasized how data scientists determine which types of neural networks (NN) to use, but those NNs are really just resource intensive workloads. After all, once you understand what the workload is doing, it is possible to design the best architecture to support it.
How to teach a machine, in simple terminology:
1. Define the problem.
This is what data scientists do, and then they choose or create the best neural network to solve that problem. Here’s a link to explain the math for the neurons and weights required for this training.
One common problem solved with machine learning is distinguishing images from a large dataset of pictures. In the real world, this is how your doorbell camera app “knows” when a package shows up at your door.
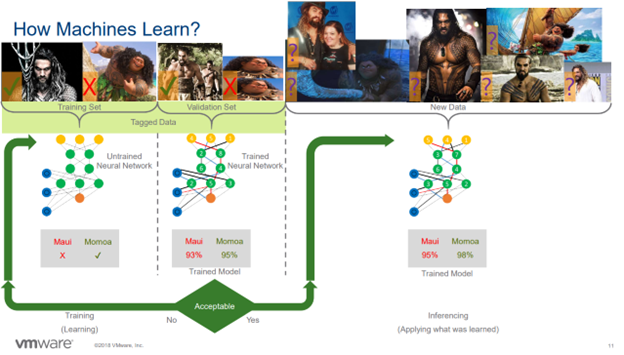
But in my presentation, the example I used was training a neural network to determine if an image was Jason Momoa or Maui from the Disney movie Moana.
2. Find or create a training dataset of tagged images.
If you’ve ever had to “prove you’re a human” to access a site by choosing all the stoplights, you’re actually helping to tag images for a training dataset! You are saying “this image contains a stop light,” and eventually you’ll have a large collection (data set) of stop lights.
3. Run the untrained neural network against the training dataset.
It should also be tested against a validation dataset (another set of tagged images). The training set will teach the neural network what makes a file Momoa and what makes it Maui.
This happens by using a lot of math and programing. Neural networks are made up of “neurons” that can accept inputs and produce outputs. The neurons are all connected, and they signal each other as information is processed. Each connection has a weight, and that is what determines the outputs of the entire network.
The data scientists will adjust the weights of the neural network as they are training it, until they feel that they can trust the results.
4. Run the trained model and run it against a new dataset.
Now that the neural network knows how to solve the problem with the training data, it’s time to test it with data which the model hasn’t seen before.
We can make “intelligent machines.”
Now you understand how to teach machines to do things like see the difference between a picture of Momoa and a picture of Maui. Conceptually at least. We’re at a pretty interesting time. We have huge amounts of digitized data that can be used as datasets. We have the ability to create pretty complex computer programs (neural networks) and modern server power that can crunch all of this data and make connections that have meaningful implications for society.
AI isn’t something to be afraid of. This is where digital transformation was leading us, and applications like ChatGPT have so much potential to do good things. However, charging into this new field without considering the unintended consequences is dangerous. We’ll discuss that in upcoming posts.
What have you done with ChatGPT? Let us know in the comments!


2 thoughts on “How do you teach a machine to be intelligent?”
Comments are closed.