Most AI initiatives fail because leaders invest in tools before defining the business problem, data readiness, and infrastructure requirements. This guide gives C‑suite leaders a pragmatic AI deployment framework by clarifying executive decision ownership, managing risk, and aligning infrastructure to real‑world use cases.
C-suite leaders are experiencing 360-degree pressure from AI transformation initiatives. Boards want an AI strategy articulated yesterday. Teams want to experiment. And the C-suite must decide what’s actually worth doing. The unending noise around AI—the hype, the stories of failure, the vendor promises—makes it harder, not easier, to cut through to what matters.
The risks are real and well-documented. Job search algorithms have shown gender and age bias [arXiv, Proskauer], resulting in class-action lawsuits. Additionally, an airline’s AI agent gave false discount information, causing legal and reputational issues [Register]. And studies estimate that people are misdiagnosed due to AI models’ hallucinations [BHM].
Done well, AI does deliver with integrated workflows that reduce manual effort, sharper decision-making from better data, and meaningful competitive advantage. But “done well” requires more than selecting the right model or platform. It requires asking the right questions before you invest about your use cases, your data, your infrastructure, and your risk tolerance. This requires a pragmatic approach to AI development and deployment.
Pragmatic AI Deployment: What Leaders Need to Own
An effective starting point for a successful deployment is a workflow where you already understand the problem. Every AI deployment, regardless of scale or industry, follows the same four-stage process. Your job as a leader isn’t to master each stage technically. It’s to know what decisions you own at each one, and where the risks are most likely to derail you.
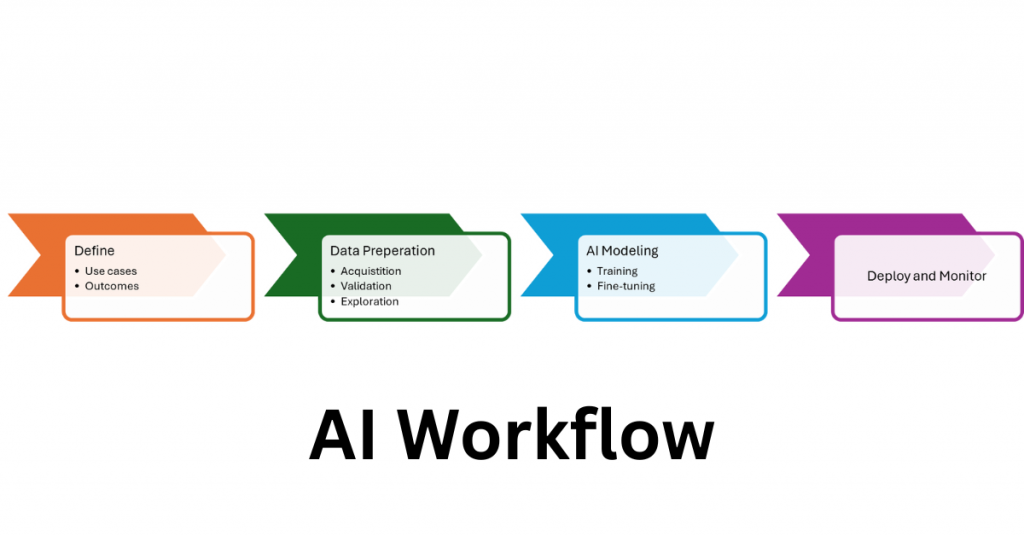
Define the Use Case
This is where many AI initiatives get into trouble: leaders fail to clearly define the problem. At this stage, your role is to push for specificity: What decision will this AI system make or support? What does success look like in six months and how will it be measured? What data do we have, and are there privacy or regulatory constraints on using it? Answering these questions before making any infrastructure decision saves significant downstream cost and rework.
Data Preparation
Data preparation can be the most labor-intensive phase in any AI project and the one most likely to expose organizational problems you didn’t know you had. Your teams will need to source, clean, and validate data from across the business, which quickly surfaces issues like siloed systems, inconsistent formats, and unclear data ownership. A 2024 survey found that 45% of leaders cite fragmented, unstructured data as a major roadblock [Huble].
As a leader, the question to ask at this stage is “do we have a data governance strategy that can support this at scale?” Without fast, scalable storage and clear data management policies, enterprise data can become the bottleneck that stalls everything downstream.
AI Modeling
This is a stage where technical complexity can seem impenetrable, and so, it is where many leaders incorrectly disengage. The core work here does belong to data scientists: selecting a foundational model, training it against your prepared data, and tuning its configuration settings (hyperparameters) until outputs align with your business use case. But the decisions that shape this stage—and its costs—are yours to consider.
The first is a build-versus-buy question. A pre-trained foundational model can be adapted to your needs faster and at lower cost, but it may not reflect the patterns specific to your industry or organization. Training a proprietary model on your own data can yield sharper results, but it requires more time, more compute, and more organizational data maturity than many teams anticipate. Knowing which path fits your situation and timeline is critical.
The second decision is infrastructure. Model training does require significant computational power, but the assumption that this means expensive GPU clusters is increasingly outdated. Advanced CPUs can handle many enterprise use cases with lower costs and power consumption. The right question to pressure-test here is “what does the model we’re choosing actually require to run?”
Deployment and Monitoring
Once the model has been trained and validated, it is ready to solve real world problems and can be moved to production. In the inference stage, it will make real-time predictions, classifications, or decisions on new data it has not seen before.
This stage introduces challenges related to scalability and cost management. As customer adoption grows, organizations must balance performance with cost-effectiveness. Continuous monitoring and updates are essential to ensure the AI model continues to deliver value over time.
Build monitoring and evaluation into your deployment plan from day one. Define the metrics that indicate the model is still delivering value, assign ownership for reviewing them, and establish a clear threshold for when retraining or intervention is required. AI is not a set-and-forget investment.
Privacy and Compliance
One consideration that runs parallel to every stage of this workflow is privacy and compliance. Sensitive or personal data must be protected throughout to avoid regulatory violations. AI models can also introduce unintended bias, making it difficult to ensure fair and transparent decision-making. This introduces a risk with real legal exposure, as the job search algorithm lawsuits cited earlier illustrate. Addressing these issues requires robust compliance strategies and regular audits, not one-time reviews.
The Most Expensive AI Decision Leaders Make
Of all the planning decisions that follow from a well-designed workflow, infrastructure investment can be the most expensive if done incorrectly. Without clarity on how models will be developed and deployed, organizations routinely overbuild, purchasing infrastructure that doesn’t match what their use cases actually require.
While we discussed how this plays out in the modeling stage above, the place where this is most acute is inference, where your deployed model meets real-world data at scale, making predictions and decisions in production. The instinct is almost always to assume this requires significant GPU investment. For many enterprise AI workloads, that assumption is wrong, and the example below shows exactly what a more calibrated approach looks like.
What Good Infrastructure Looks Like in Practice
The infrastructure question I most often hear debated is some version of: “Do we need to invest in GPU clusters to be serious about AI?” For many enterprise use cases, the answer is no, and a real-world example illustrates why. A company specializing in customer experience automation needed to deploy AI-powered chatbots at scale. Working with Intel, they leveraged 4th Gen Intel® Xeon® Scalable processors and Intel’s AI optimization tools, such as the Intel® Extension for Transformers (ITREX) and Intel® Extension for PyTorch (IPEX).
These technologies enabled the company to optimize LLM performance, achieving up to a 4x reduction in latency with configurations as small as 12-core CPUs, while maintaining accuracy. This eliminated the need for expensive GPUs, significantly reducing infrastructure costs. You can read more about the technical details in this Intel blog post.
Another emerging option is the vLLM (virtualized large language model) framework, which is optimized for CPU inference. It is perfectly suited for the Intel Xeon 6767P (64c) platform, and can also be used instead of using a GPU-heavy infrastructure for a common AI business use case: conversational chatbots [Intel].
Pragmatic AI Deployment Starts With the Right Questions
The leaders who get AI right aren’t the ones who invest in the most advanced technology. They’re the ones who ask the right questions before they invest at all: What specific problem are we solving? What does our data actually look like? What infrastructure do we genuinely need?
That last question is worth sitting with. The chatbot example above achieved a 4x reduction in inference latency without a single GPU by applying the right optimization tools to hardware that was already in the data center. That’s not a corner case. For many enterprise AI workloads, it’s the rule. Intel Xeon CPUs, combined with tools like ITREX and IPEX, give organizations a practical on-ramp to production AI that doesn’t require betting the infrastructure budget on a technology cycle that’s still evolving.
Start with a problem worth solving. Build a workflow that lets you learn fast. And don’t assume you need to rebuild your infrastructure from the ground up to achieve pragmatic AI deployment.

